Unit Testing in Perl
This tutorial will cover the basics of unit testing in Perl.
Table of Contents
What is unit testing?
Unit testing is a way to test individual components of code with automatic verification. We did manual unit testing in our last tutorial by ensuring "Hello, World!" was displayed, but what if we needed to verify multiple scripts? We will inevitably forget to verify that a change in one function didn't break another function, and then lose a night of sleep debugging our code.
This sounds hard / I'm ready to start
Unit testing in Perl couldn't be easier. You run unit tests just like
normal code (e.g., perl MYFILE). There are just two functions you
need to remember:
is(EXPERIMENTAL_VALUE, EXPECTED_VALUE, OPTIONAL_MESSAGE)isnt(EXPERIMENTAL_VALUE, EXPECTED_VALUE, OPTIONAL_MESSAGE)
You will be using is() the most. To use these functions, paste the
following boilerplate code into a file called simple.t (Perl tests
use t for test file extensions):
use diagnostics; # this gives you more debugging information use warnings; # this warns you of bad practices use strict; # this prevents silly errors use Test::More qw( no_plan ); # for the is() and isnt() functions #### # <insert test cases here> ####
You will write a lot of tests throughout this course, so you should probably create a macro in your editor (or just bookmark this page).
A simple example
Since we're just getting started with Perl, let's see how to use the
is() and isnt() functions with a cheesy example. We'll then cover
an actual scenario.
In this simple case, let's verify that our variable $class is always
"bioinformatics". In simple.t, place the following lines after the
"insert test cases here" comment:
my $class = 'bioinformatics'; is($class, 'bioinformatics', 'We are in bioinformatics!'); isnt($class, 'microbiology', 'We are not in microbiology!'); is($class, 'microbiology', 'This test case should fail...see why?');
Go ahead and run this code:
perl simple.t
You should get output like this:
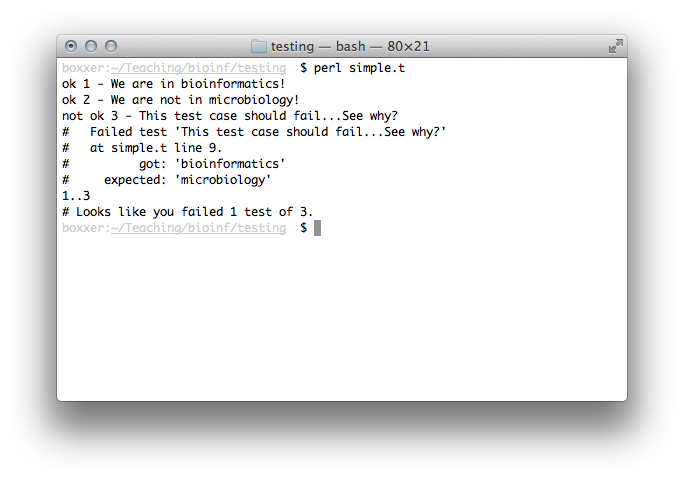
We failed that last example because $class is set to
"bioinformatics", not "microbiology".
An example scenario
Let's say we need a program to complement DNA strings (we've gotten lazy). Here are the steps we should take:
- Define the input, output, and process
- Setup the project (create stub functions and unit test contracts)
- Run the tests
- Code until the tests pass
Defining the input, output, and process
An "IPO chart" is a great way to define simple programs on a notecard.
- inputs
- A string of DNA, e.g., "ACGTATTA"
- output
- A string of RNA, e.g., "ACGUAUUA"
For the process, write out pseudocode:
- Get input
- Convert all Ts to Us
- Return the complemented string from #2
Setup the project
Create a file complement.pl on your computer with the following
contents:
use diagnostics; use strict; use warnings; sub complement { }
Next, create a test file complement.t with the following contents:
use diagnostics; use warnings; use strict; use Test::More qw( no_plan ); do 'complement.pl'; # tests go here
If we run our tests now with perl complement.t, we'll get the
following:
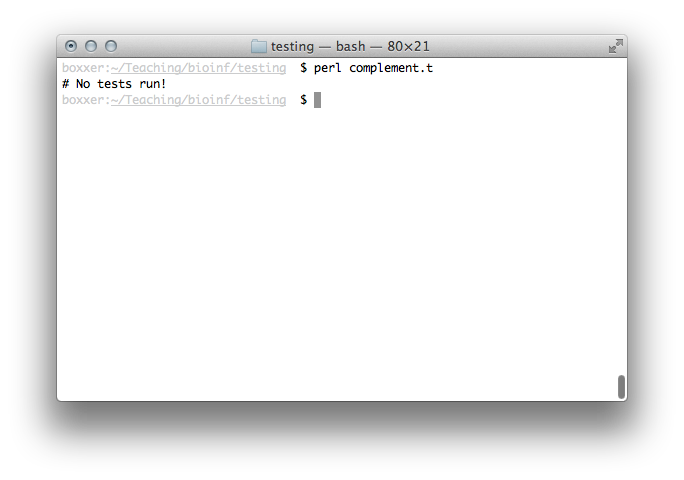
Good! We don't have any errors, so let's define our tests. These can
be viewed as "contracts" for our complement() function – it should
always work for these examples.
Add the following to complement.t:
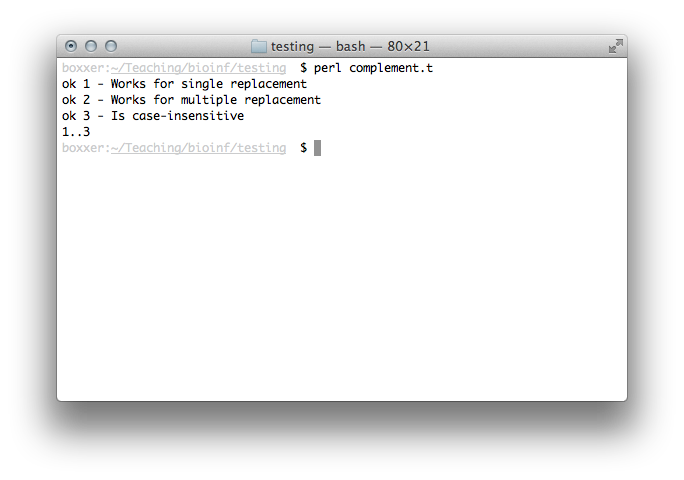
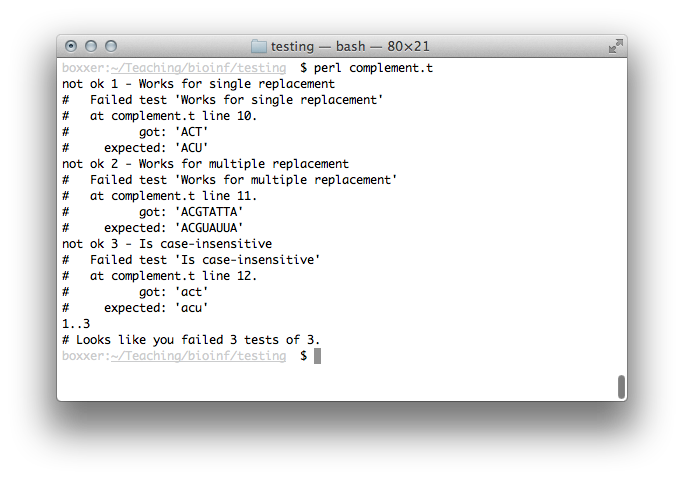
is(complement('ACT'), 'ACU', 'Works for single replacement'); is(complement('ACGTATTA'), 'ACGUAUUA', 'Works for multiple replacement'); is(complement('act'), 'acu', 'Is case-insensitive');
Go ahead and run this:
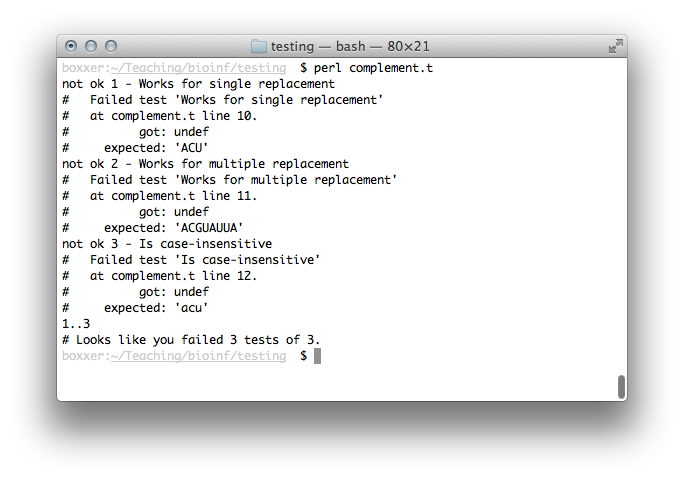
It looks like we've got work to do. There are a number of things
wrong, but the first is the returned value – Perl is giving an
undef, which is short for undefined. Let's at least make our
complement() function take input and spit it back out:
sub complement { my $str = shift; return $str; }
Run the code again:
If we refer back to our IPO chart, we've now completed #1 and part of #3. Let's do the actual work.
In Perl, there's the transliteration operator tr that looks like
this:
$str =~ tr/FIND/REPLACE/;
Our "FIND" is T and our "REPLACE" is U, so let's implement this:
sub complement { my $str = shift; $str =~ tr/T/U/; return $str; }
Run the code again:
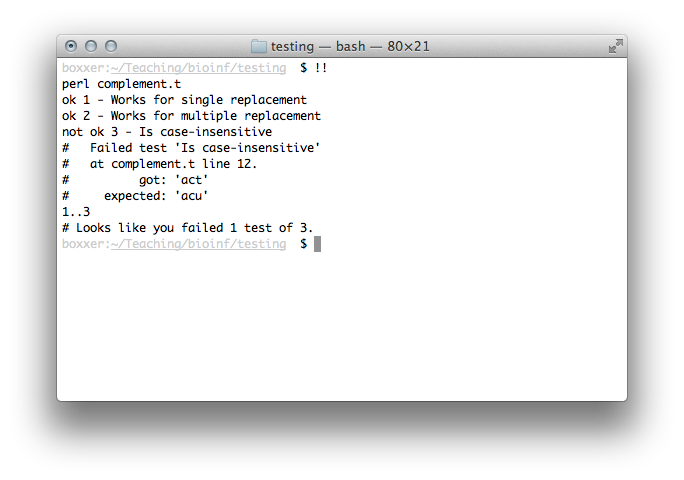
We're passing for everything but lowercase! We can easily fix this.
tr does a positional mapping, so if you had a tr call like this:
$str =~ tr/ABC/DEF/;
you would have the following search-replace table:
| Search Char | Replace Char |
|---|---|
| A | D |
| B | E |
| C | F |
We can use this knowledge to construct a lowercase "t" to lowercase "u" mapping:
sub complement { my $str = shift; $str =~ tr/Tt/Uu/; return $str; }
Run the code again: